

Introduction
Hey there! My name's Graham, and for the past few months my team and I have been working on Pilot: a framework that helps small development teams adopt multi-cloud deployment strategies.
This post will mostly be a casual reflection of what we learned while building Pilot. If you're interested in even more of the nitty gritty details, you can find our write-up link at the top of this post.
Alright, with that out of the way, let's talk about platforms.
Platform-as-a-Service
Heroku. Elastic Beanstalk. App Engine. What do all these have in common?
Right! The letter 'e'!
No? Okay okay, seriously this time.
They are all some form of a Platform-as-a-Service, which allow developers to deploy their applications by abstracting away the need to configure the necessary infrastructure.
Platforms-as-a-Service (or PaaS) aren't a new concept - in fact, there's a fascinating story about how Canon (yes, the camera company) could have become a major cloud provider almost 15 years ago before Zimki, the PaaS-like service they were building, ultimately got shut down. The core motivation behind PaaS has been around as long as development has been around. Developers have always wanted to just focus on their code without wrangling the complexity of getting that code into a production environment.
However, application topologies have become increasingly complex as more and more companies have been adopting Infrastructure-as-a-Service offerings. The days where production environments are a simple 3-tier architecture are mostly behind us - this is thanks to amazing strides in technology like Docker, Kubernetes, and others which allow for much more robust environments.
This complexity is only increasing as companies also adopt multi-cloud strategies - meaning they utilize services across different cloud providers. This requires much more DevOps expertise and manpower than using just a single cloud provider. If you're interested in some of the reasons why companies are adopting this strategy, you can find some interesting statistics in HashiCorp's State of the Cloud Survey.
Why an Internal Platform?
With the advent of Infrastructure-as-a-Service and Serverless offerings, companies can stitch together much more complex infrastructure patterns than they used to, such as Yubl's architecture depicted below.
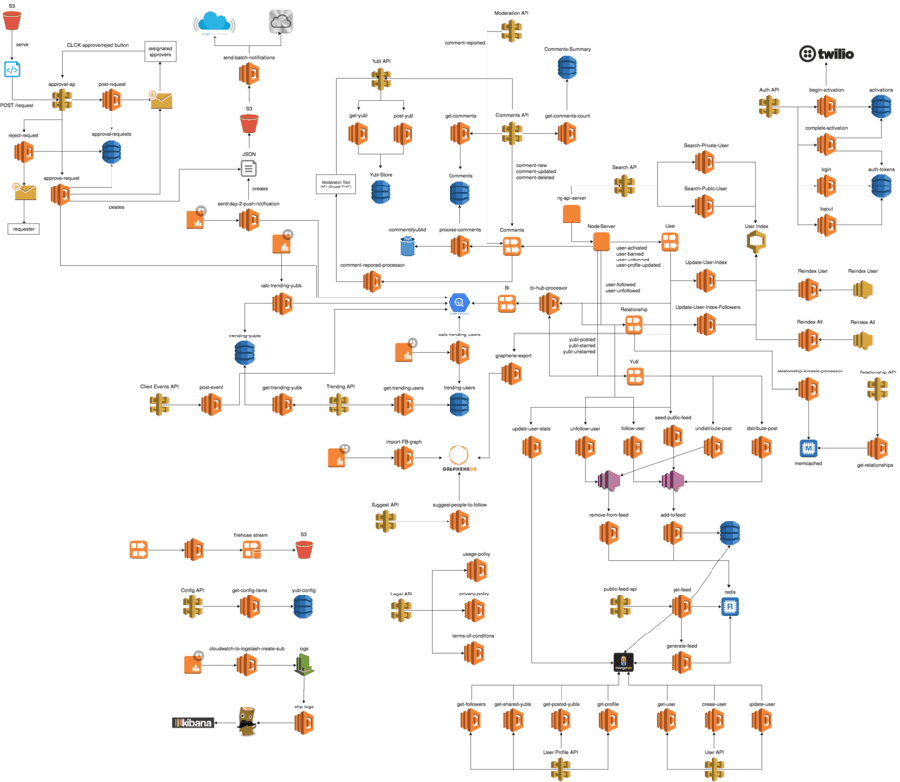
Because of this, companies like Netflix and Atlassian have built their own internal platforms that developers can use which are geared towards their use cases; however, not all companies have the budget nor the resources necessary for building internal platforms, so they resort to solutions like Heroku.
The downside to this is that developers lose the ability to control and configure their platforms while also getting locked-in to a single vendor. In addition, they typically also pay extra platform fees on top of the infrastructure fees they're already paying.
This is why we built Pilot, which is a very minimalist framework for setting up an internal platform - all running on your own infrastructure using your supported cloud provider of choice. We provide sensible defaults so that novices can get their apps up and running, but also allow more experienced users to configure the platform to their needs - you can even dig into the generated Terraform configuration files if you want even more control when provisioning your platform.
The Basics of Pilot
The skeleton of Pilot is rather straight-forward. The lifeblood of Pilot runs through our Pilot Server, which is a virtual machine that contains our custom Docker image with everything we need for the deployment lifecycle.
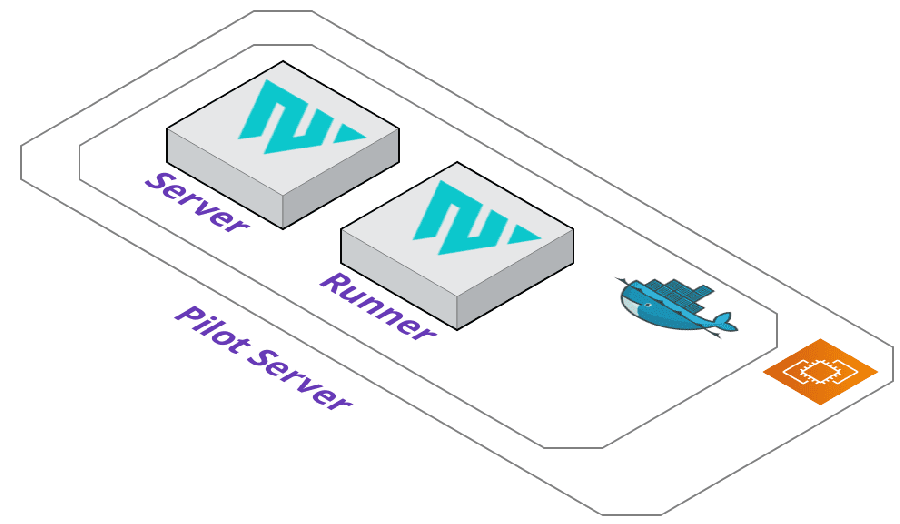
We decided to extend a fairly new tool: HashiCorp's Waypoint. This allowed us to focus on implementing more features for our CLI and deployment pipeline since there were already core features we really enjoyed using (such as their fantastic user interface).
With a single command, you can set up an internal platform on either AWS or GCP. No matter where the platform sits, you can deploy to any supported cloud provider after the server is provisioned by running the configure command with the respective flag.
When deploying an application, we generate a Waypoint configuration file that our server needs to deploy your application. While we default to using some of our custom plugins and Waypoint's built-in plugins, you can always use Waypoint's documentation to tweak the configuration as needed. This means that deploying applications can be simple if you want it to be, while providing an extensible deployment pipeline if your infrastructure pattern becomes more complex.
The same goes for our Pilot Server. By default we provision a Pilot Server, then run Waypoint processes using Pilot's custom Docker image; however, you own it and have full control of it. We provide the ability to use Waypoint's default image during initial setup as well and, if you're feeling adventurous, you could dive in to the guts of the server and customize your platform to suit your needs.
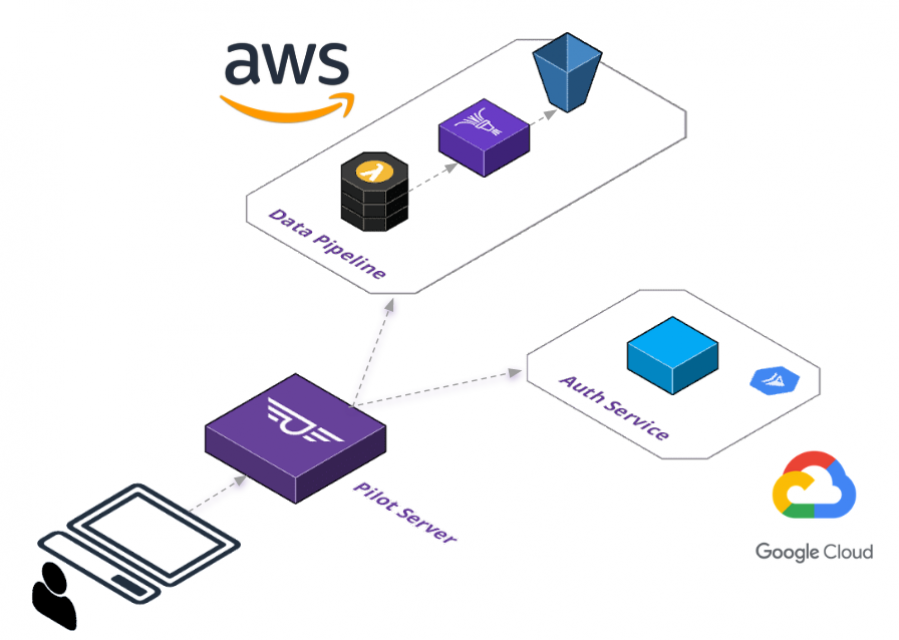
This allows for deployment patterns such as the one depicted above. After running a straight-forward setup process and a little custom configuration with the help of documentation, you can deploy a service to Google Cloud Run and a function to AWS Lambda - all using the same platform and deployment pipeline. Other options are CDNs like AWS Cloudfront or Google's Cloud CDN, along with any currently supported resource that is built-in to Waypoint.
Technical Lessons Learned
Since there were quite a few, I'll talk about my favorite technical challenge we came across. As a reminder, for more in-depth technical details you can view our write-up.
Configuring Docker-in-Docker
A challenging aspect of implementing remote Waypoint operations was figuring out how to execute Docker processes. For applications that utilize Cloud Native Buildpacks (Pilot's go-to build process), the environment needs to be able to access the Docker daemon for image builds and pushing to a container registry. There are several Docker-in-Docker methods that you can use to accomplish this, so let's take a quick look at two of them.
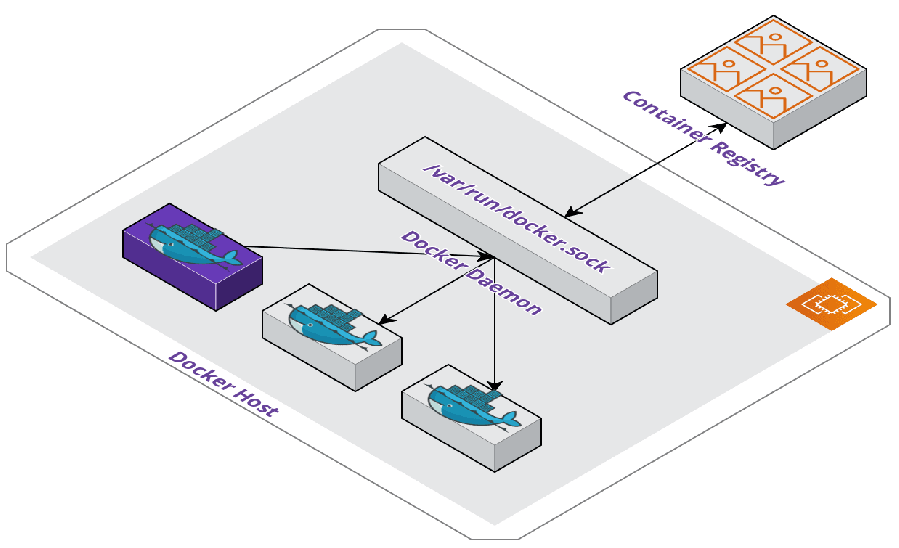
Mounted Unix Socket
The first method uses the Docker daemon's Unix socket. Docker commands are executed from a container with the socket's path mounted and a local Docker binary installation. This allows a container to execute Docker commands with all of the operations actually occurring on the underlying machine, typically referred to as the Docker host.
Running a Privileged Container
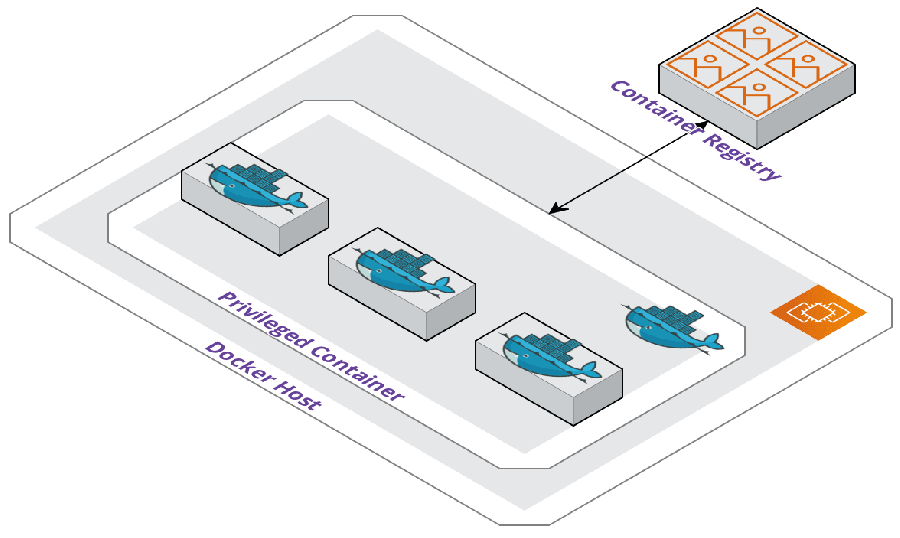
The second method uses an outer container started from an official Docker-in-Docker image that Docker maintains. The container needs to be started in privileged mode, which can have adverse side effects. This is because the container will get full access to all devices on the Docker host. Consequently, this is the same access to the host as any processes running outside of containers, which can be a security flaw if the privileged container were compromised.
Issues with Docker-in-Docker
Evaluating these two approaches highlighted some problems with Docker-in-Docker if we wanted to implement remote operations (a very crucial aspect of our platform).
With the first approach in mind, we didn't want to add extra bloat to our custom image with a Docker installation if all we needed were simple build and push capabilities for deployments.
Another issue is that Waypoint handles starting the server and runner containers. This means we wouldn't have a straight-forward way to control the mounting of the Docker socket as discussed in the first approach or starting the runner in privileged mode seen in the second approach.
After further research, we discovered a way to turn our Docker host into a Docker server.
Configuring a Docker Server
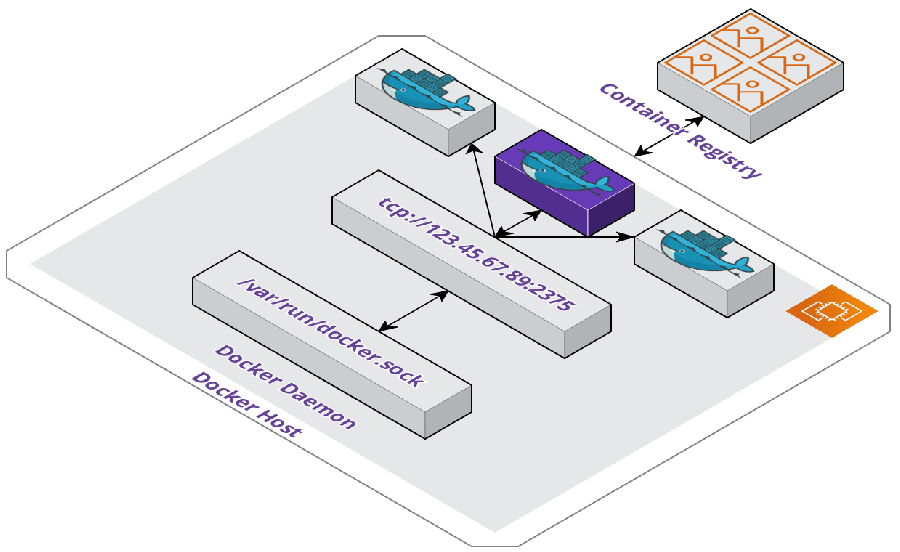
Our solution was to make the Docker host - our Pilot Server - a Docker server by exposing the Docker daemon as an API for the runner container to consume. This looks and feels like Docker-in-Docker, but technically isn't since there's not a Docker installation on the runner container and all Docker operations are still handled on the Docker host.
After configuring the virtual machine with the proper settings, we were able to set an environment variable on the runner container which contained the Pilot Server's IP address. This lets the runner know where the Docker host is located on the network and will send requests via the proper endpoints.
Other Lessons Learned
Building Pilot taught all of us a lot of lessons, not all of them technical. I'll talk about some of the ones that stood out to me as some of the most important ones.
Working Asynchronously
One of my favorite parts about working on Pilot was working asynchronously as part of a diverse, geographically distributed team. However, this introduced a very important facet that gets brought up time and time again: communication is the most important aspect of a team.
There's a fine line between being able to get into your flow state to focus on tackling a problem and becoming a hermit. If you're an experienced developer, I'm sure you've been in plenty of meetings that could have just been an email, taking away precious development time. This is why asynchronous work is so great as a developer. However, make sure to consistently communicate and rely on your team. You're on a team for a reason - this journey isn't one to be taken alone.
Reaching Potential
Honestly, if you told me back in May that by August I would have built something like Pilot, I probably would have laughed. A lot of us struggle with impostor syndrome, that I know. And while it's something I've struggled with for a long time, I've realized with Pilot that one of the best cures is to just put yourself into a position where you have to deliver - you'll end up surprising yourself.
This goes hand-in-hand with working on a team. We all challenged each other to go farther and reach higher than we would have been able to as individuals. In the same vein, it's easy to get lost in a project. Having reliable team members to support you and even encourage you to step away from your computer every now and then was crucial to our success as a team.
Conclusion
I hope you enjoyed reading this little reflection as much as we enjoyed building Pilot. Currently, Pilot is still in an alpha state, and since we primarily built Pilot to challenge ourselves and augment our skills, it's unlikely that we'll continue to maintain it.
After completing this journey, the 3 of us are now ready for our next endeavors and looking for full-time work. If you're interested in reaching out to any of us, you can find all of our contact information here.
